
Many internet service providers try to rent customers combination modem/routers for $10-$20 per month. I generally advise people who are slightly tech-savvy to save money by buying their own modems and routers. There’s an exception to my advice that applies to Xfinity Internet customers.
On many Xfinity plans, there’s a 1.2TB per month cap on data use.1 The options an Xfinity customer has for removing the cap depend on whether a customer is renting an xFi modem. Customers that don’t rent a modem have to pay an extra $30 per month for unlimited data. Customers that already rent an xFi modem for $14 per month can pay an extra $11 ($25 per month) for xFi Complete. With xFi Complete, customers get unlimited data by default.
Here’s a table from Xfinity’s page on Xfi Complete that describes various options:
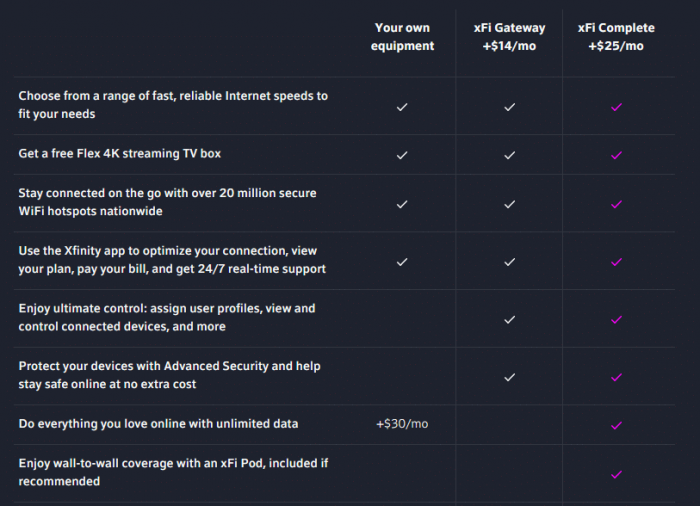
While the large majority of Xfinity customers won’t exceed 1.2TB of data use, tech-savvy customers that own their own equipment likely use more data than the average customer. Oddly enough, renting a modem with xFi Complete is cheaper than buying your own equipment and upgrading to unlimited data.2









