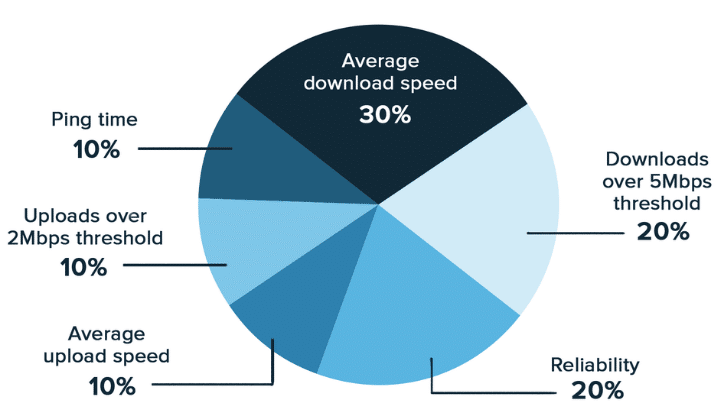
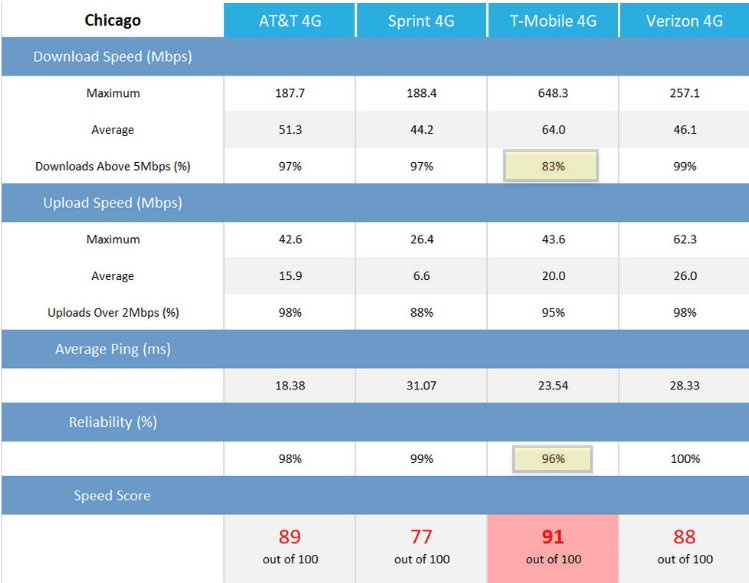
On Wednesday, the FCC released a fascinating report related to the Mobility Fund Phase II (MF-II). The MF-II is a planned program to provide federal funding for network build-outs in rural areas that are underserved by 4G coverage.
To determine which geographic areas were underserved, the FCC requested coverage maps and data from network operators. After reviewing the data and allowing outside entities to challenge the datas’ reliability, the FCC became concerned about the accuracy of the information shared by T-Mobile, U.S. Cellular, and Verizon. The FCC decided to conduct its own performance tests and compare the results of its tests to the information the network operators provided. Here’s what the agency found:1
Incentives
When considering the accuracy of coverage maps, I try to think about the incentives network operators face. When advertising to consumers, network operators often have an incentive to overstate the extent of their coverage. However, incentives can run in the opposite direction in other situations. For example, when trying to get approval for a merger between Sprint and T-Mobile, Sprint had incentives to make its 4G coverage profile look limited and inferior to the coverage profiles of other nationwide networks.2
I’m not well-informed about the MF-II, so I don’t feel like I have a good grasp of all the incentives at play. That said, it’s not clear that all network operators would have an incentive to overstate their coverage. A network operator that claimed to offer coverage in an area it didn’t cover may limit competitors’ access to subsidies in that area. However, a network operator erroneously claiming to cover an area may prevent itself from receiving subsidies in that area.
Challenges
After network operators submitted coverage information to the FCC, a number of entities, including both governments and network operators, were allowed to challenge the validity of coverage information submitted by others. Here’s a bit more detail about the challenge process:3
About a fifth of the participating entities went on to submit challenges:4
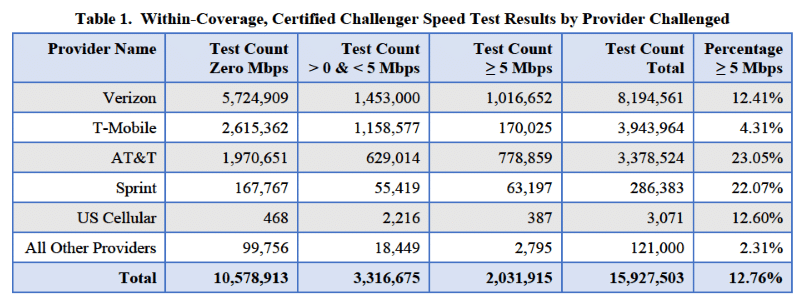
The challenge data often showed failed tests and lackluster speeds in areas where network operators claimed to offer coverage:5
During the challenge process, some parties entered specific concerns into the record. For example:6
After reviewing the challenges, the FCC requested additional information from the five largest network operators (AT&T, T-Mobile, Verizon, Sprint, and U.S. Cellular) to understand the assumptions involved in the networks’ coverage models.
FCC tests
Around the same time the FCC was requesting additional information from network operators, the agency also began its own testing of Verizon, U.S. Cellular, and T-Mobile’s networks. These speed tests took place in 12 states and primarily made use of a drive-testing methodology. As mentioned earlier, analyses of the FCC’s test data suggested that the on-the-ground experience with Verizon, T-Mobile, and U.S. Cellular’s network was much different than the experience that would be expected based on the information the networks provided to the FCC.
What happened?
A lot of the commentary and news articles I’ve seen in response to the FCC’s report seem to conclude that network operators are bullshitters that intentionally lied about the extent of their coverage. I have reservations about fully accepting that conclusion. Accurately modeling coverage is difficult. Lots of factors affect the on-the-ground experience of wireless subscribers. The FCC largely acknowledges this reality in its report:
Further supporting the idea that assessing coverage is difficult, the FCC didn’t just find that its tests contradicted the initial information submitted by network operators. The FCC data also contradicted the data submitted by those who challenged network operators’ data:

While the FCC found some of the information submitted by networks to be misleading about on-the-ground service quality, I don’t believe it ended up penalizing any network operators or accusing them of anything too serious.10 Still, the FCC did suggest that some of the network operators could have done better:
FCC response
The FCC concluded that it should make some changes to its processes:12
Reflections
The FCC’s report illustrates how hard it is to assess network performance. Assumptions must be made in coverage models, and the assumptions analysts choose to make can have substantial effects on the outputs of their models. Similarly, on-the-ground performance tests don’t always give simple-to-interpret results. Two entities can run tests in the same area and find different results. Factors like the time of day a test was conducted or the type of device that was used in a test can have big consequences.
If we want consumers to have better information about the quality of service networks can offer, we need entities involved in modeling and testing coverage to be transparent about their methodologies.